
 2024.10.30
2024.10.30 
 浏览量:
浏览量:
在数字化浪潮席卷全球的今天,数据科学已成为推动社会进步和行业发展的关键力量。为了进一步促进教师队伍提升科研与社会服务能力,高质量反哺应用型人才培养,并助力区域、城市的数字化发展,数据科学学院推出“做有用的科研”系列专栏。本系列旨在报道分院教师队伍在行业洞察、政策解读、数据分析、案例研究以及人才培养等方面的研究成果和思考。通过“以研促教,以教促学”的策略,展现教师在科学研究、教育教学以及行业应用中的综合素养,为行业雇主的未来发展贡献智慧与力量。

作者简介:史博文,数据科学学院数据科学与大数据技术专业教师,拥有12年通讯行业从业经历(中国电信、中兴通讯),有丰富的实践经验和理论基础。研究方向运用大数据、机器学习等先进技术解决通信领域的实际问题,在基站覆盖智能优化方面取得显著成果。参与并主导多项重要项目,如马来西亚无线大数据应用项目、贵州电信VMAX项目、匈牙利NetMAX项目,在大数据应用和网络优化方面有较深厚功底。
一、研究背景
在现网中,存在许多低效覆盖的基站,如信号遮挡、信号快衰等问题,这些问题严重影响了无线网络的覆盖和质量。传统的识别方法,如测试、天面现场勘察等,虽然能够发现问题,但效率低下,无法满足大规模网络优化的需求。而现有的MR(Measurement Report, 测量报告)平台虽然具备一些大数据核查功能,但缺乏针对低效覆盖站点的有效核查手段。因此,我们迫切需要一种高效、准确的数字化方法来识别这些低效覆盖基站。
本研究以MR定位数据为基础,通过编写Python程序输出拟合后的全网小区的覆盖图谱,探索出一套基于机器学习方法对线性拟合的斜率和截距进行智能判别,从而识别低效覆盖基站的方法。
二、解决方案及效果
1、MR数据定位
目前常用的定位方式有三种:
(1)基于终端应用的GNSS定位信息,终端打开了含有定位信息的应用,相应的测量报告中含该类定位信息;
(2)基于基站TA、特征数据RSRP利用距离信息,通过几何运算得到的三角定位数据;
(3)应用K最近邻 (k-Nearest Neighbor,KNN)分类算法,在GNSS建立的特征空间(TA\RSRP)中,当一个三角定位样本附近的k个最近(即特征空间中最邻近)样本的大多数属于某一个空间,则该样本也属于这个类别,这个过程也称之为指纹定位。基于特征数据RSRP、TA建立的特征库,对三角定位数据进行二次定位聚类,缩小定位误差。
指纹定位思路如下:
计算步骤1:
计算每个位置指纹数据与定位点数据之间的欧氏距离,计算公式如下:
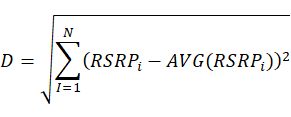
计算步骤2:对欧氏距离进行从小到大排序。
计算步骤3:使用TA值校准步骤2中生成的数据。
2、低效覆盖站点识别方案
2.1 按小区聚合MR数据
先计算MR数据库中,所有MR采样点与小区的距离;再按照小区维度,聚合输出固定距离区间(100米)与RSRP值对应数据,并进行数据清洗滤除室分小区及MR采样点不足的数据。

图1 聚合示意图
2.2 利用Python进行线性关联
基于python库np.polyfit,对每个小区距离、RSRP数据,进行线性关联,得到每个小区覆盖与距离的斜率(信号衰减系数)、截距(站下RSRP),并绘制小区级覆盖图谱。

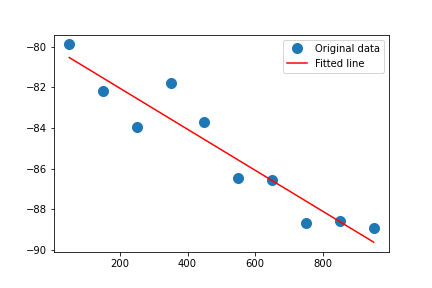
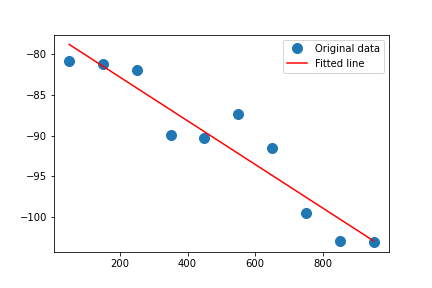
图2 绘制的小区覆盖图谱
2.3 信号遮挡小区识别
通过筛选截距低的小区,即站下信号强度差的小区,可以识别信号遮挡小区。

图3 信号遮挡小区识别
查看疑似遮挡小区的MR覆盖图,基站附近RSRP低于-85dBm,存在信号遮挡的情况。

MR图例
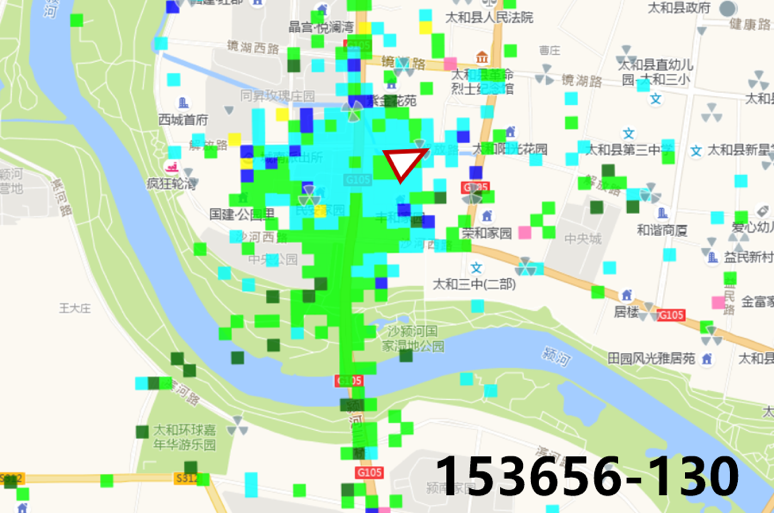
图4 MR验证
2.4 信号快衰小区识别

图5 快衰小区识别
快衰识别采用的是支持向量机(SVM)模型,实现数据加载、数据划分、过采样处理、特征标准化、模型构建和训练。
在构建机器学习模型的过程中,正确地划分数据集是至关重要的一步。这不仅涉及到模型的训练效果,更直接关系到模型在实际应用中的泛化能力。为了准确评估模型对未见数据的预测能力,通常将数据集分为训练集和测试集两部分。训练集用于模型的学习和调整,而测试集则作为评估模型性能的标准。在本研究中,采用了80%-20%的划分比例,即使用数据集中80%的数据作为训练集,剩余的20%则保留作为测试集。
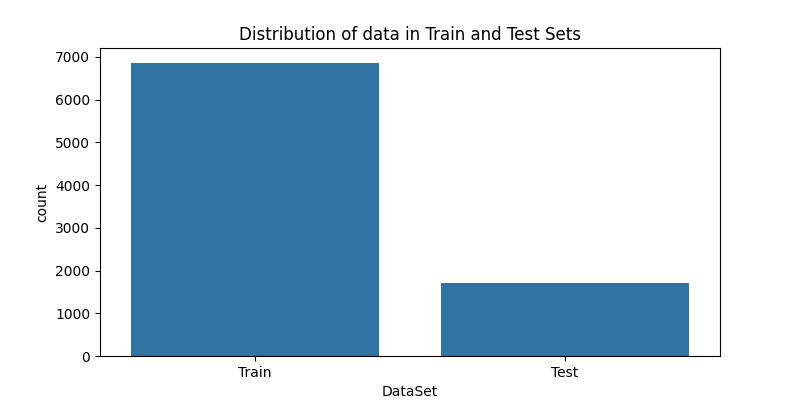
图6 快衰小区判断
采用支持向量机(SVM)作为分类器,选用线性核函数,并设置正则化参数C为1。SVM通过寻找最优的超平面来区分不同类别的数据,线性核函数适用于特征维度较高或者样本量不是很大的情况。训练过程中,模型在经过SMOTE处理和特征标准化后的训练集上进行训练。
在测试集上评估模型的性能,模型评估结果如下所示。
Model accuracy: 0.9529100529100529
Precision: 0.7213114754098361
Recall: 0.6153846153846154
F1 Score: 0.6641509433962264
根据以上指标,我们可以得出如下信息:
1. 准确率(Accuracy):模型的准确率为约95.29%,这表明在整个数据集上,模型正确分类的样本占总样本数的比例。
2. 精确度(Precision):模型的精确度约为72.13%,这表示模型正确预测为正类别的样本占所有预测为正类别的样本的比例,较高的精确度意味着模型能够减少误报的可能性。
3. 召回率(Recall):模型的召回率约为61.54%,也称为灵敏度或真正类别率,表示模型能够正确识别出真正的正类别样本的能力。
4. F1分数(F1 Score):模型的F1分数约为66.42%,是精确度和召回率的调和平均值,综合了模型的准确性和全面性。
综合来看,模型的准确率较高,但精确度和召回率的表现相对较低,可能存在一定程度的假阳性和假阴性。因此,在实际应用中需要根据具体业务需求和成本考虑来调整模型的阈值,以平衡精确度和召回率,并进一步改进模型的性能。
在训练完模型后,使用测试集数据进行预测,并通过混淆矩阵和分类报告来评估模型的性能。混淆矩阵提供了预测的真实正例和假正例的数量,而分类报告则提供了精确度、召回率、F1得分细节。此外,还可以通过ROC曲线和AUC值来评价模型在不同阈值下的表现,AUC值越高,表明模型的性能越好。

图7 混淆矩阵图
图6观察到模型在测试数据集上的表现。混淆矩阵是分类问题的一个标准工具,它显示了实际类别与模型预测类别之间的关系。以下是对图中结果的分析:
1. 真负类(True Negatives,TN):在这个混淆矩阵中,真负类是指被正确预测为负类别(0)的样本数量。在这里,有1713个样本被正确分类为负类别(0),这些是模型正确识别的负类别样本。
2. 假正类(False Positives,FP):假正类是指实际上是负类别(0),但被错误地预测为正类别(1)的样本数量。在这个混淆矩阵中,有34个样本被错误分类为正类别(1)。
3. 假负类(False Negatives,FN):假负类是指实际上是正类别(1),但被错误地预测为负类别(0)的样本数量。在这个混淆矩阵中,有55个样本被错误分类为负类别(0)。
4. 真正类(True Positives,TP):真正类是指被正确预测为正类别(1)的样本数量。在这个混淆矩阵中,有88个样本被正确分类为正类别(1),这些是模型正确识别的正类别样本。
5. 总样本数:这个混淆矩阵中的总样本数为1811,是所有预测结果的总和。
在此图中,可以看出,模型对负类的预测相当准确,有1713个TN。然而,有34个实例被错误地分类为正类(FP),这可能导致漏检,即模型未能识别出所有的正类。虽然有55个FN,这意味着有55个正类被误判为负类,但与TP相比,这个数目相对较小。TP数量较高,说明模型对正类的预测也是准确的。
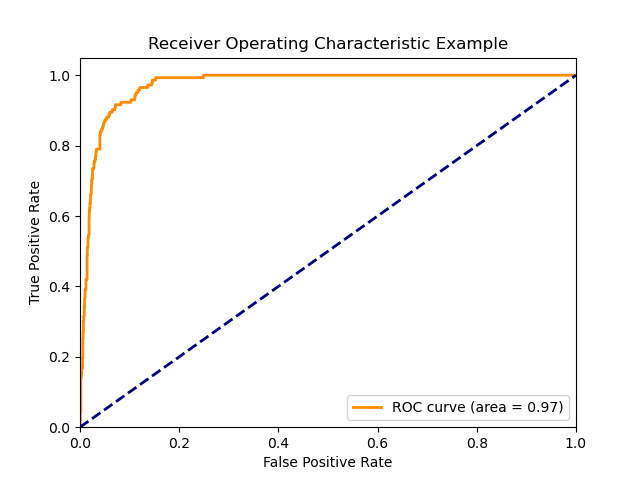
图8 ROC曲线图
ROC(Receiver Operating Characteristic)曲线图中,曲线下方的区域(AUC,Area Under the Curve)反映了模型整体的分类性能。理想的ROC曲线会远离对角线,尽可能接近左上角,表示模型具有很高的真正类率(True Positive Rate,TPR)和很低的假正类率(False Positive Rate,FPR)。图中的ROC曲线显示,AUC的值为0.97,这意味着模型在正确分类样本方面表现突出。
通过对5346条标记后的数据进行的建模,然后对2385条未标记数据进行预测,模型预测结果表明2385条基站数据中有95条数据存在快衰问题。
接下来我们从预测出的95条问题数据中随机抽取2个进行DT测试验证,验证结果显示这2个小区均符合快衰特征。(测试结果如表2所示)

三、总结与展望
本研究利用现有MR数据,通过大数据分析拟合、自动绘制小区覆盖图谱等数字化手段,成功检测出了符合低效覆盖特征的小区。这一方法的实施不仅提高了基站覆盖优化的效率,还为后续的网络优化工作提供了有力的支持。未来,我们将结合不同的覆盖场景,对方法和程序进行进一步的细化和修正,以期取得更加显著的成果。同时,我们也希望这一研究能够为通信行业的数字化发展贡献一份力量。
参考文献
[1]Lyu M .Optimal Base Station Network Based on Topological Data Analysis[J].International Journal of Modeling and Optimization,2022,12(1).
[2]N. Atienza, R. Gonzalez-Diaz, and M. Rucco, “Persistent entropy for separating topological features from noise in vietoris-rips complexes,” J. Intell. Inf. Syst, vol. 52, no. 3, pp. 637–655, 2019.
[3]Liu H Y ,Tuo C Y ,Hsu Y C , et al.Predicting malfunction of mobile network base station using machine learning approach[J].IEICE Proceeding Series,2019,59
[4]Wei Xiao. A probabilistic machine learning approach to detect industrialplant faults. arXiv preprint arXiv:1603.05770, 2016.
[5]Jian L ,Jibin W ,Umar S A A .High Accuracy Signal Recognition Algorithm Based on Machine Learning for Heterogeneous Cognitive Wireless Networks[J].Journal of Communications,2017.
[6]贾子寒,王西点,徐晶等.基于机器学习的基站故障根因分析方法研究[J].电信工程技术与标准化,2023,36(09).
[7]马敏,刘武韬,吴晓曦等.4G/5G无线网络智能运维研究与应用[J].电信工程技术与标准化,2022,35(08):44-50.
学校地址:陕西省西安市雁塔区东仪路8号
Copyright 2017 Xi'an Eurasia University , All Rights Reserved , 陕ICP备13005465-1



