
 2026.03.19
2026.03.19 
 浏览量:
浏览量:
前言
在数智化浪潮席卷全球的今天,AI及数据科学已成为推动社会进步和行业发展的关键力量。为了进一步促进教师队伍提升科研与社会服务能力,高质量反哺应用型人才培养,并助力区域数智化发展,数据科学学院推出“Data Lab”系列专栏。本系列旨在报道分院教师队伍在行业洞察、政策解读、数智分析、案例研究以及人才培养等方面的研究成果和思考。通过“以研促教,以教促学”的策略,展现教师在科学研究、教育教学以及AI数据应用中的综合素养,为行业、企业的未来发展贡献智慧与力量。
作者简介

数据科学与大数据技术专业教师蒲晓霞
研究方向:大数据分析与机器学习,主持各级课题3项,发表论文3篇,负责智慧医疗产品开发项目、负责多智能体开发项目等。
主讲课程:《算法与数据结构》、《数据库技术与应用》、《python程序设计》等课程。
01
研究背景
肥胖已成为全球范围内日益突出的公共健康问题。随着生活方式的转变以及高热量饮食的广泛普及,肥胖发生率持续上升,不仅对个体健康产生长期影响,还与糖尿病、心血管疾病等多种慢性疾病密切相关,同时也对社会医疗体系与经济发展带来持续压力。传统研究多依赖统计方法分析肥胖相关因素,而在数据科学不断发展的背景下,机器学习为肥胖问题研究提供了新的技术路径。通过整合饮食习惯、运动行为、遗传背景等多维度健康数据,可以更加系统地识别影响肥胖形成的关键因素,并对个体肥胖风险进行预测,从而为精细化、个性化的健康管理提供数据支撑。基于数据挖掘与机器学习方法开展肥胖研究,有助于深化对肥胖形成机制的理解,并为公共健康管理与干预策略的制定提供科学依据。
02
模型的理论概述
2.1 XGBoost算法理论
2.1 XGBoost算法理论
XGBoost(eXtreme Gradient Boosting)是一种基于梯度提升框架的高效集成学习算法,其核心思想是通过迭代方式不断构建新的弱学习器,以逐步修正已有模型的预测误差。该方法通常以决策树作为基学习器,在每一轮训练中根据当前模型的预测结果计算损失函数的梯度信息,并利用这些梯度来生成新的决策树,使模型在不断叠加树结构的过程中持续优化预测性能。同时,XGBoost在模型训练过程中引入正则化项以控制模型复杂度,从而在提高模型泛化能力的同时有效降低过拟合风险,使其在处理结构化数据预测问题时具有较高的准确性与稳定性。
2.2 SHAP理论
2.2 SHAP理论
SHAP(SHapley Additive exPlanations)是一种用于解释机器学习模型预测结果的方法,其理论基础来源于合作博弈论中的 Shapley 值。该方法将模型中的每个特征视为参与者,将模型预测结果视为收益,通过计算特征在不同特征组合下对模型输出所产生的边际贡献,从而衡量各特征对预测结果的影响程度。SHAP 方法能够在统一的理论框架下量化特征的重要性,不仅可以解释整体模型中各特征的贡献程度,还可以对单个样本的预测结果进行细粒度解释。通过将模型预测值分解为基线值与各特征贡献值之和,可以清晰地揭示不同特征在模型决策过程中的作用,从而提高机器学习模型的可解释性,为模型结果的理解和应用提供重要依据。
03
数据获取与预处理
本文所使用的数据来源于Kaggle平台的数据集,该数据基于墨西哥、秘鲁和哥伦比亚居民的饮食习惯与身体状况信息构建,用于评估个体的肥胖程度。数据集共包含2 111条样本记录和17个特征变量,涵盖饮食行为、生活方式以及个体基本身体信息等多个方面。其中,饮食相关变量包括高热量食物摄入频率(FAVC)、蔬菜摄入频率(FCVC)、每日主餐次数(NCP)、两餐之间进食情况(CAEC)、每日饮水量(CH20)以及酒精摄入情况(CALC);身体活动与生活方式变量包括是否监测卡路里摄入(SCC)、身体活动频率(FAF)、电子设备使用时间(TUE)以及主要交通方式(MTRANS);此外,还包含家族肥胖史、性别、年龄、身高和体重等个体基本信息。由于某些特征变量和目标变量为类别变量,无法直接进行 XGBoost分类预测的模拟,所以需要提前对其进行量化处理:如分别用0和1表示性别为女性和男性;NObesity(肥胖水平)从0至6分别表示为体重不足、体重正常、超重I级、超重II级、肥胖类型I、肥胖类型II和肥胖类型Ⅲ,即数字越大代表肥胖水平越高。因为体重和身高直接影响了样本的肥胖水平。所以在进行机器学习模拟之前,删去体重和身高变量。随后对其他特征变量进行相关性分析,结果如图1所示。
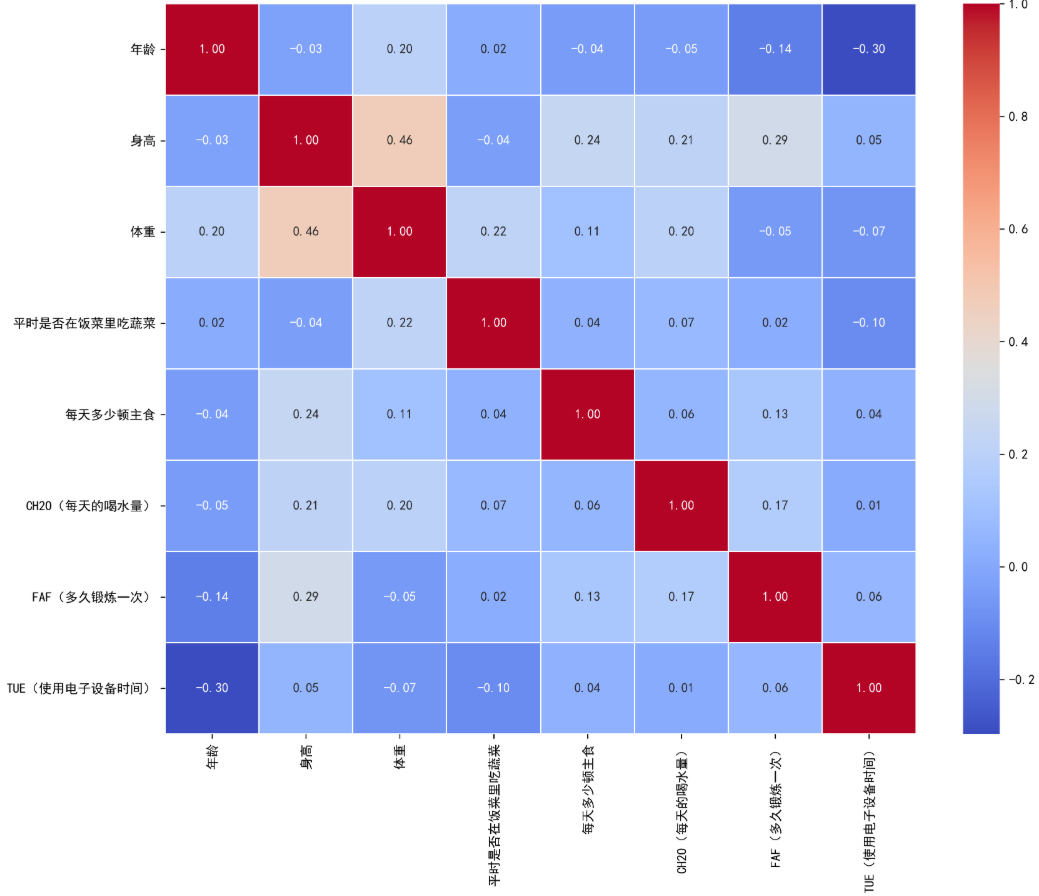
图1 特征相关性热力图
由图可知,各特征变量间的相关性水平均不高,最高为0.57,且特征变量间的相关性水平并不相似,因此不存在多重共线性问题,无须再剔除特征变量。将处理后的数据集按照 4:1进行划分,其中80%作为训练集,20%作为测试集,最终将数据集划分为1689个训练样本和422个测试样本。
04
模型评估与解释
4.1 预测模型的评估
4.1 预测模型的评估
为评估不同机器学习模型在肥胖水平预测任务中的表现,本文选取 XGBoost、随机森林(Random Forest)以及支持向量机(SVM)三种常见算法进行对比实验,并从准确率(Accuracy)、精确率(Precision)、召回率(Recall)以及 F1 值四个指标对模型性能进行综合评价。实验结果如表1所示。
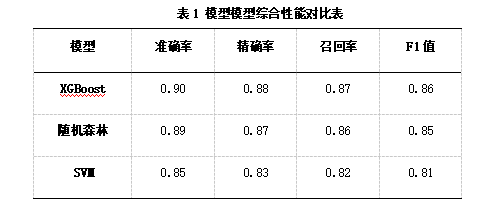
从实验结果可以看出,三种模型均能够较好地完成肥胖水平预测任务,但在整体性能上仍存在一定差异。其中,XGBoost 模型在四项评价指标上均取得最高得分,准确率达到 0.90,精确率、召回率和 F1 值也均优于其他模型,表现出更强的预测能力和稳定性。随机森林模型整体性能略低于 XGBoost,但仍保持较好的分类效果;相比之下,SVM 模型在各项指标上相对较低。综合比较可知,XGBoost 在处理该肥胖数据集时具有更好的预测效果,因此本文选取 XGBoost 作为最终分析模型。
4.2 可解释性分析
4.2 可解释性分析
在上述工作的基础上,为进一步理解模型的决策机制,本文引入 SHAP 方法对 XGBoost 模型进行可解释性分析。通过计算各特征的 SHAP 值,并统计其平均绝对值,可以直观反映不同变量在模型预测过程中的影响程度。图2展示了影响肥胖水平的重要特征排序结果。
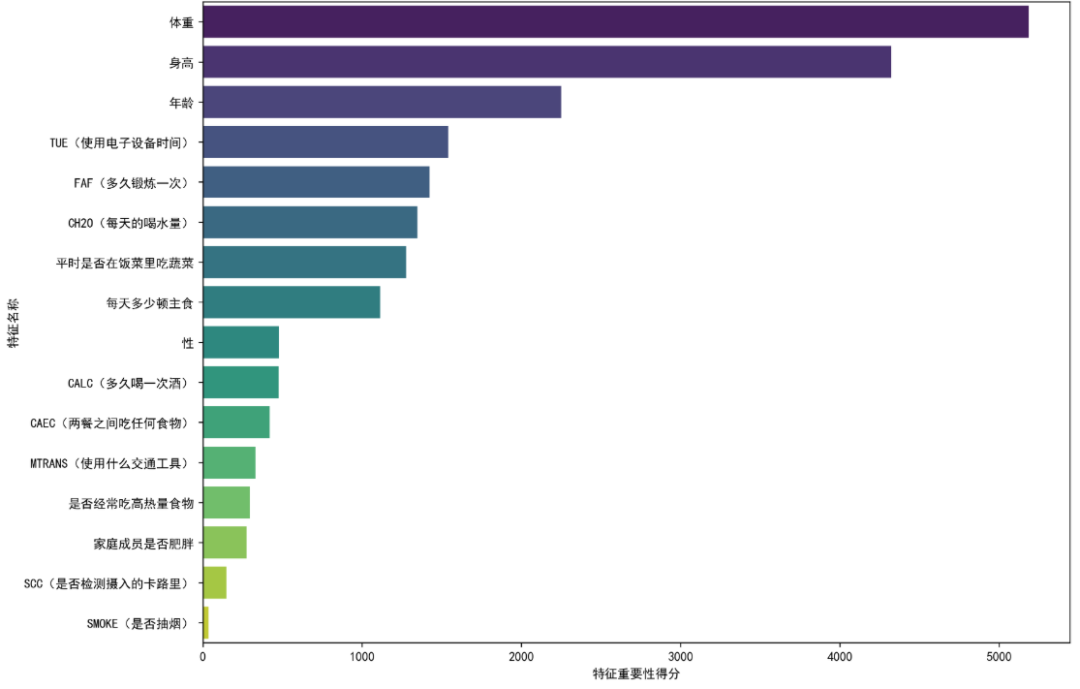
图2 特征重要性分析图
分析结果表明,基本身体特征体重、身高、年龄是最重要的预测因素,而生活习惯和饮食因素次之,个人行为习惯(如是否抽烟)的影响相对较小。“年龄”表明个体年龄变化与肥胖风险之间存在较为明显的关联。此外,“两餐之间的食物摄入情况”和“蔬菜摄入频率”等饮食相关变量同样具有较高的重要性,说明饮食习惯在肥胖预测中发挥着关键作用。性别对模型结果具有一定影响,但整体贡献程度处于中等水平。相比之下,“每日饮水量”“酒精摄入情况”以及“卡路里摄入监测”等变量的SHAP值较低,对模型预测结果的影响相对有限,而“是否吸烟”对预测结果几乎没有显著贡献。
总体来看,肥胖水平的形成主要受到遗传背景、年龄结构以及饮食行为等因素的综合影响,而部分生活方式变量虽然存在一定关联,但其影响程度相对较弱。该结果为进一步理解肥胖形成机制以及制定健康干预策略提供了数据支持。
05
总结与建议
本文基于个体饮食行为与身体状况等多维数据,构建机器学习模型对肥胖水平进行预测,并结合SHAP方法对模型结果进行解释分析。研究结果表明,XGBoost模型在多项评价指标上表现出较优的综合性能,能够有效完成肥胖水平的分类任务;通过SHAP可解释性分析,进一步识别出家族肥胖史、年龄及饮食习惯等关键影响因素,揭示了不同特征在模型决策过程中的作用机制。
总体来看,机器学习方法为肥胖风险评估提供了可靠的技术手段,而可解释性分析的引入提升了模型结果的透明度与可理解性,有助于从数据层面深化对肥胖形成机制的认识。在应用层面,相关研究结果可为健康管理提供数据支持,通过针对关键影响因素进行干预,在饮食结构优化、生活方式调整及风险人群识别等方面形成更加科学的决策依据,从而为肥胖预防与公共健康管理提供有效支撑。
参考文献:
[1] 黄东升.基于XGBoost的肥胖水平综合预测与SHAP模型解释分析[J].现代信息科技,2025,9(7):40-46.
[2] 伍洁,陈迪芳,李瑞彤,等.基于XGBoost和SHAP方法的个人信贷风险评估研究 [J].现代信息科技,2024,8(8):146-150+155.
数据科学学院智研研究院,专注于行业研究、AI及数据洞察分析,依托大数据技术、人工智能与商业场景融合,为企业提供专业研究服务和定制化解决方案,欢迎合作交流。
联系人:蒲老师
地址:西安欧亚学院数据科学学院
学校地址:陕西省西安市雁塔区东仪路8号
Copyright 2017 Xi'an Eurasia University , All Rights Reserved , 陕ICP备13005465-1



