
 2025.04.03
2025.04.03 
 浏览量:
浏览量:
在数字化时代背景下,数据科学已成为驱动社会进步与行业革新的核心动力。秉承学校“以雇主为导向,以学生为中心”的教育理念,同时响应雇主对高素质数据分析人才的需求,数据科学学院特别推出“数据知识分享”系列专栏。本专栏旨在普及数据模型、数据结构、机器学习等基础数据科学知识,为师生提供持续学习和成长的平台,同时,通过连接教学理论与现实实际,在生动传递专业知识的同时,深化教师队伍的知识储备,助力应用型数据分析人才的培养。
作者简介:彭娟, 管理科学与工程博士,研究专长:供应链金融、博弈论、数据分析与挖掘,主讲课程:《回归分析与实现》,《机器学习基础》,《数据可视化》等。
还在为选机器学习模型头秃吗?别急!这份「模型使用说明书」用最接地气的比喻,带你快速掌握8大模型的优缺点,从此告别选择困难症!
01
线性回归(Linear Regression)
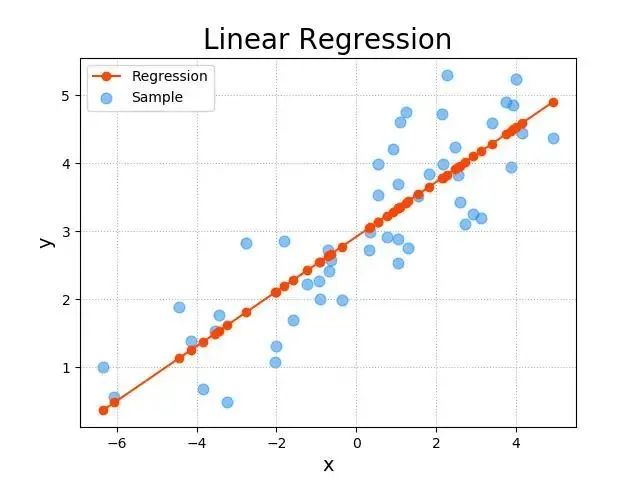
📌 特点:简单直男,一根直线走天下。
📌 适用:预测房价、销量等“越…越…”的问题(比如“面积越大,房价越高”)。
⚠️ 缺点:不懂浪漫(非线性关系),遇到复杂问题就懵圈。
02
K近邻(KNN)
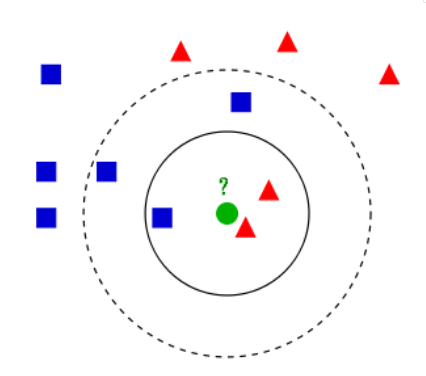
📌 特点:随波逐流,永远跟着邻居投票。
📌 适用:推荐系统(比如“喜欢A的人也喜欢B”)、简单分类。
⚠️ 缺点:
•计算量爆炸:预测时要遍历所有数据,大数据集直接卡成树懒!
•维度诅咒受害者:特征超过20维?精度断崖式下跌,惨过股灾!
•平等强迫症:所有特征同等重要?现实中明明"年龄比星座重要"啊!
03
决策树(Decision Tree)
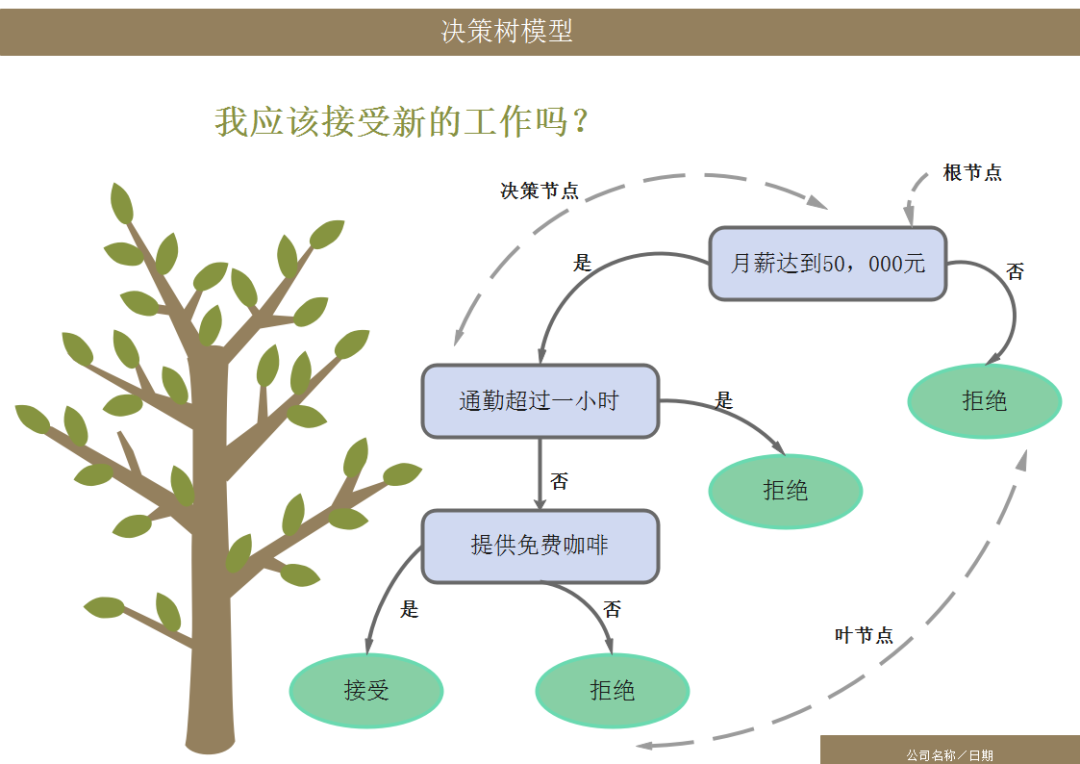
📌 特点:逻辑狂魔,疯狂问“如果…就…”。
📌 适用:分类和回归都行,比如判断用户买不买商品、预测天气。
💡 优点:解释性强,像流程图一样好懂!
⚠️ 缺点:玻璃心,数据稍微一抖,树结构就大变样——像用不同答案问Siri,每次都能被气笑。
04
随机森林(Random Forest)
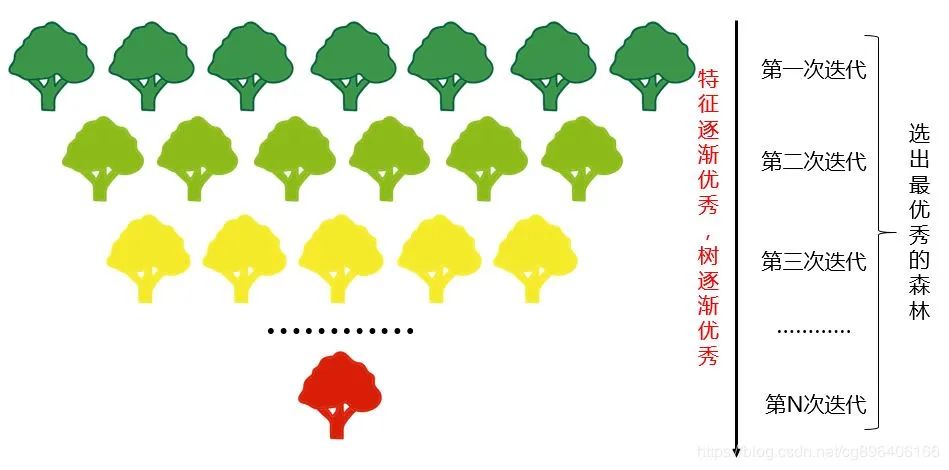
📌 特点:民主天团,一群决策树投票决定结果。
📌 适用:表格数据(如金融风控、医疗诊断),抗过拟合能力强。
⚡ 优势:比单棵决策树更准,还能告诉你哪些特征最重要!
⚠️ 缺点:树多话痨,百上千棵树一起预测,速度比XGBoost/LightGBM慢几拍,像老年人集体过马路
05
XGBoost / LightGBM
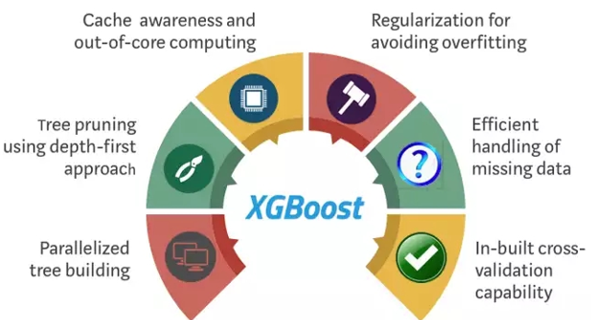
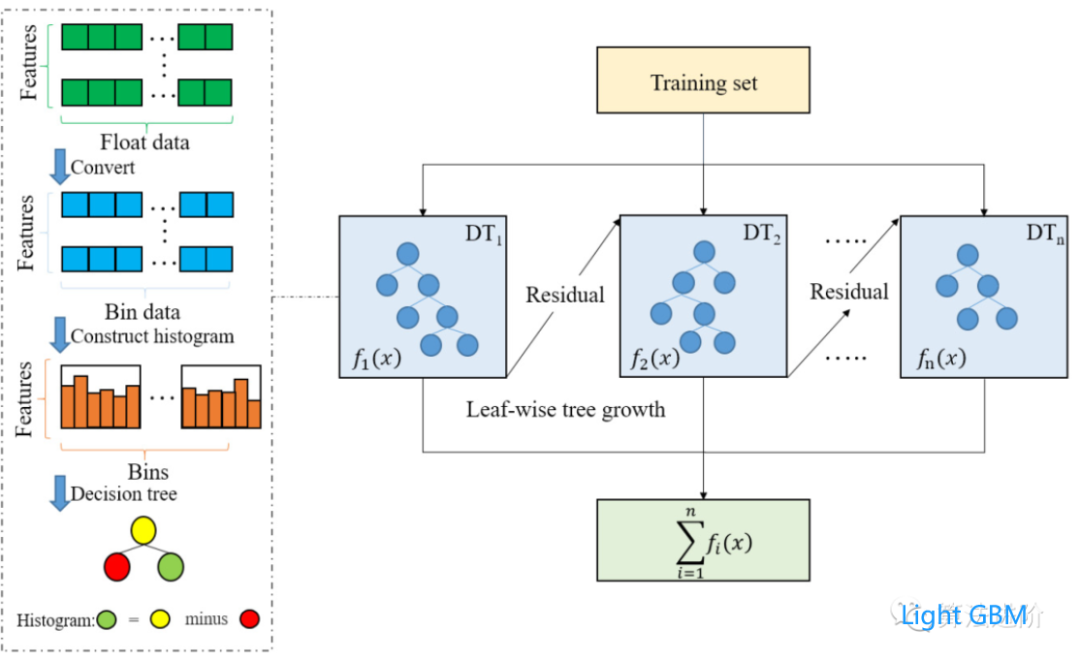
📌 特点:学霸中的战斗机,迭代训练时专注“错题”(残差)。
📌 适用:Kaggle比赛常胜将军!结构化数据预测(如用户流失、广告点击率)。
🔥 区别:
LightGBM:速度之王,大数据集上快如闪电。
06
支持向量机(SVM)
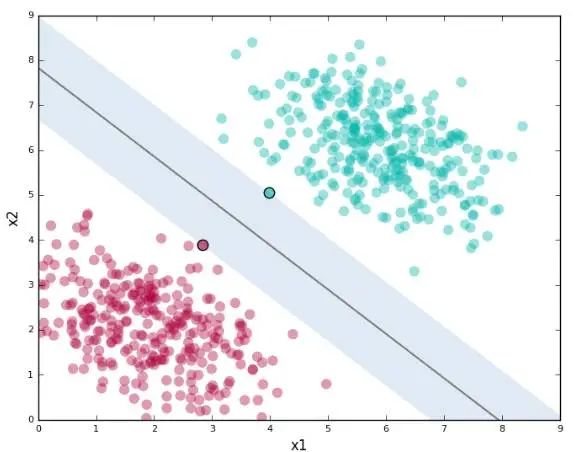
📌 特点:边界控,拼命画线把数据分开。
📌 适用:小数据集分类(比如手写数字识别),高维数据表现优秀。
⚠️ 缺点:
计算慢如蜗牛:数据量超过1万条?准备好和咖啡机做朋友吧!
调参像玄学:核函数选不好,效果直接扑街,堪比开盲盒。
07
神经网络(Neural Network)
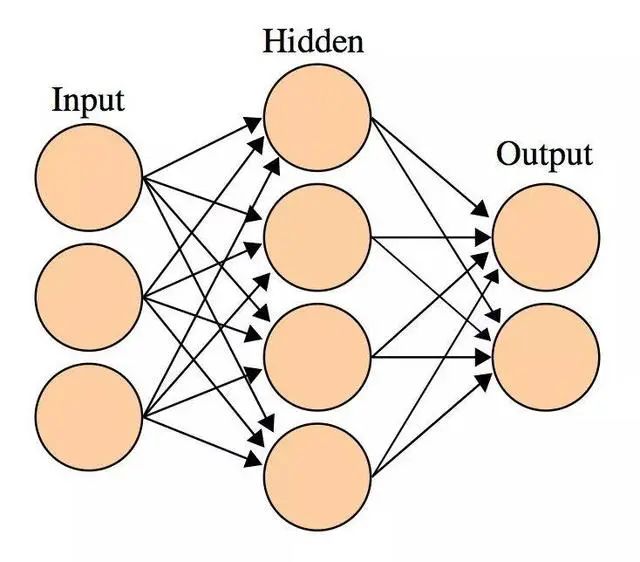
📌 特点:超级学霸,隐藏层越多越能学复杂模式。
📌 适用:图像、语音、自然语言处理(比如人脸识别、ChatGPT)。
⚠️ 缺点:
数据饥渴症:没个百万级数据,连个水花都溅不起来!
黑箱操作王:决策过程像魔术,解释性?不存在的!
08
LSTM(长短期记忆网络)
📌 特点:记忆力超群,擅长处理时间序列(比如股票价格、语音信号)。
📌 适用:预测未来趋势(天气、销量)、自然语言生成(写诗、聊天机器人)。
💡 优势:能记住长期依赖,不像普通RNN“转头就忘”。
⚠️ 缺点:
训练速度感人:等它跑完时序数据,隔壁XGBoost都刷完10轮Kaggle了!
参数多到炸:输入门、遗忘门、输出门...调参像在开航天飞机!
短序列杀鸡用牛刀:数据短于100步?传统模型反而更香!
🔍 极简模型选择指南
问题类型 | 推荐模型 |
结构化数据分类/回归 | XGBoost、LightGBM、随机森林 |
时间序列预测 | LSTM、XGBoost(简单时序) |
图像/语音/文本 | 神经网络(CNN/Transformer) |
快速原型开发 | 决策树、KNN |

机器学习就像组建战队——没有最强的单一模型,只有最合适的组合!下次遇到数据难题,记得根据场景pick你的"超级英雄"战队!
学校地址:陕西省西安市雁塔区东仪路8号
Copyright 2017 Xi'an Eurasia University , All Rights Reserved , 陕ICP备13005465-1




