
 2025.09.06
2025.09.06 
 浏览量:
浏览量:
在人人都是自媒体的时代,你是否想过:一个视频封面图的色彩搭配,如何影响百万点击?一句标题的措辞选择,怎样决定用户是否驻足?当流量成为UP主变现的核心筹码,数据科学如何为创意赋能?
2025年暑期,西安欧亚学院数据科学学院联合狗熊会推出《深度学习进阶:基于多模态数据的视频播放量预测模型》在线实习项目。18名学员沉浸式体验从“封面图+标题”到播放量预测的全链路实战。用代码解码自媒体商业逻辑,用模型丈量创意的价值边界。
Part 01.
项目介绍:
当非结构化数据遇见AI
本项目聚焦短视频平台核心指标——视频播放量预测,以封面图与标题文本为双核心要素,搭建完整的多模态数据融合建模流程:
业务逻辑拆解:
从用户注意力获取到点击行为转化,解析“封面图+标题”对播放量的驱动机制
技术实战路径:
基于真实抓取的视频数据集(含封面图、标题、播放量等),完成图像特征提取(迁移学习)、文本向量化(NLP处理)、多模态模型构建三大核心任务
成果价值输出:
输出可直接用于UP主选题优化、平台推荐策略的播放量预测模型
Part 02.
项目任务体系:
从像素到预测的硬核训练
TASK1 封面图特征工程
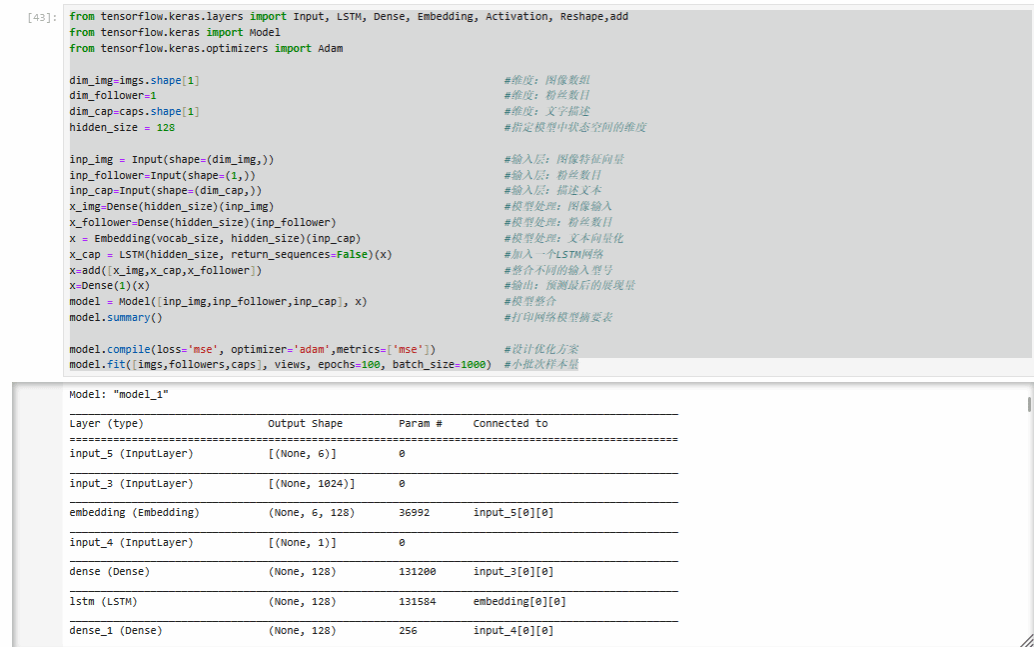
学生需基于ResNet50和MobileNet预训练模型,通过迁移学习提取封面图的高层特征,经全局平均池化生成固定长度向量,构建图像特征矩阵。结合图像增强,对比不同方案对效果的影响,筛选最优特征提取策略。
TASK2 标题文本向量化
学生需对视频标题进行中文分词与高频词筛选,利用Keras工具转化为固定长度的数值序列。同时,基于BERT模型提取语义特征,并融合TF-IDF关键词特征,构建兼具语义与关键词信息的混合文本表示,为多模态建模提供输入。
TASK3 多模态融合建模
学生需融合图像、文本与粉丝数特征,构建全特征回归模型,并通过剔除单类特征的对比模型,分析各类数据对预测的贡献。同时设计图像与文本的融合结构,对比线性回归、XGBoost与神经网络的预测效果,以MSE为指标筛选最优方案,输出关键影响因素与最终模型。
Part 03.
项目亮点:
技术+业务的双重跃迁
1. 紧扣自媒体商业场景:聚焦短视频平台核心指标,直击UP主流量焦虑,学完即懂爆款视频的底层逻辑。
2. 贯通多模态数据处理全流程:从图像处理(OpenCV/Keras)到文本分析(NLP/BERT),掌握非结构化数据格式化的核心技能。
3. 实战导向的代码训练:提供Jupyter Notebook代码模板+云GPU环境,手把手完成从数据清洗到模型部署的闭环
4. 双向能力提升:技术端可以精通Keras框架、多模态建模、迁移学习等前沿工具;业务端可以理解用户注意力经济规律,建立数据驱动的创作思维。
5. 成果可量化可落地:输出可视化分析报告+可复用预测模型,简历直通互联网大厂AI岗位
Part 04.
学员实践感悟:
从“感觉”到“算法”的认知革命
在项目初期,我总以为“标题越夸张,点击率越高”,但通过TF-IDF分析,我们发现平台用户更偏好“悬念式+痛点型”标题。比如“99%的人都不知道的XX技巧”这类句式,其CTR比普通陈述句高出23%。最让我惊喜的是,我们用BERT提取标题语义时,发现用户对“免费”“揭秘”等词的响应特别敏感,原来流量密码藏在词频和语义之间!
——统本数据2302 高正钦


这次实习让我第一次意识到,原来短视频背后的流量逻辑是可以被“算出来”的。以前做自媒体账号,标题靠灵光一现,封面图靠审美直觉,播放量全凭运气。但通过这个项目,我用BERT分析标题语义,用ResNet提取封面特征,再把它们融合建模预测播放量,整个过程像搭积木一样清晰。这次我真正把课堂学的Python、机器学习,用在了实际场景里。 这种“学了就能用”的成就感,是以前考试拿高分都比不了的。
——统本数据2304(双语) 向婷婷

Part 05.
结语:用AI重新定义内容创作
从像素到预测,从标题到流量,《深度学习进阶:视频播放量预测》项目让学生深刻体会到:在注意力稀缺的时代,数据科学正在重塑内容创作的底层逻辑。
未来,西安欧亚学院数据科学学院将持续落实“雇主导向、学生中心”教学理念,持续推出“技术+垂直行业”融合型项目,助力学生在AI+传媒、AI+营销、AI+教育等交叉领域,走出独特的数智化职业发展路径。
学校地址:陕西省西安市雁塔区东仪路8号
Copyright 2017 Xi'an Eurasia University , All Rights Reserved , 陕ICP备13005465-1



